This article outlines a workflow for creating, modifying and migrating the database schema (and data) with MySQL and PHP-orientated tools.
Inception
I’m starting a new web application project, have talked to the client at length and have a decent understanding of the problem domain. Time to analyse and think about the data architecture of my application. I’ll use the data modelling feature of MySQL Workbench, a free tool for visual database design (and more).
With the help of my handy ERD design tool it’s easy to lay out the groundwork for my database schema. I’ll create new tables and columns as I try to figure out the best architecture for my database. Foreign key relationships are easy to manage. Comments, notes and layers add additional information.
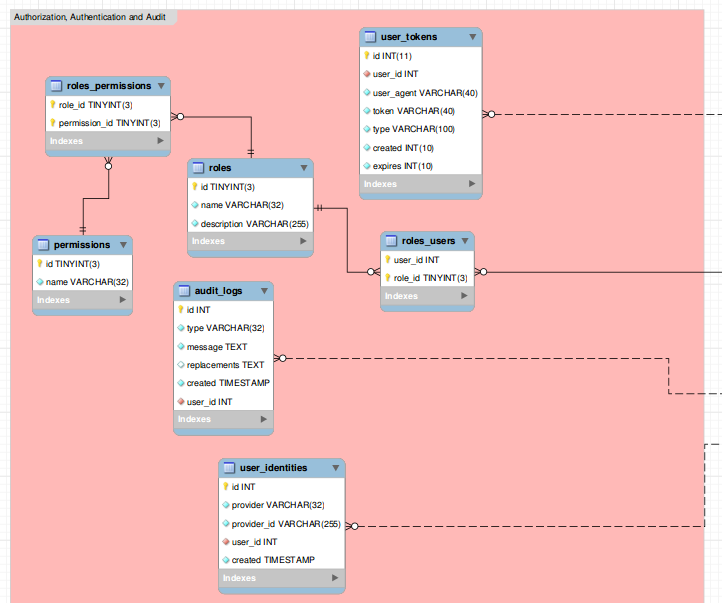
I can also insert some initial data to my tables, to be populated upon SQL import. An example for this would be the predefined entries of the roles table. Triggers, stored procedures and other MySQL goodies are also manageable from the model.
When I’m satisfied with my initial design, I’ll use the Export option and generate SQL from my model.
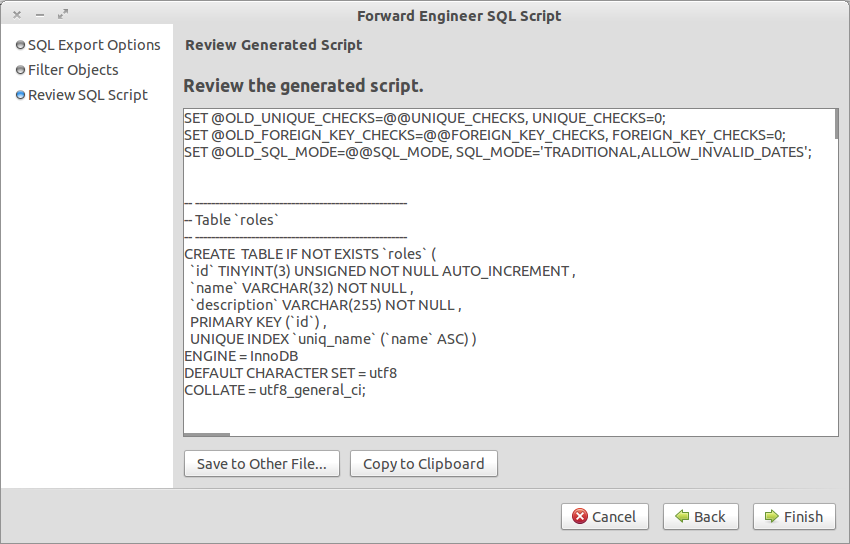
The generated SQL file goes to my project folder along with the saved model (.mwb) file. I’ll update them as I change the schema. The generated file goes into a new MySQL database as the initial dump.
Initial Development
I now have a visual model of my database that I can easily update at will. Time to get started with the application code. I’ll probably discover quite quickly that some table need modification or I’m missing an entity from the schema altogether. Time to open up the ERD model, add the missing object(s) and re-generate the SQL.
I’ve changed my model, but not the development database on my localhost. Since I almost always have my tables in InnoDB to support foreign keys, the dropping might be a bit… problematic. Try to drop the tables in the wrong order and you get a half-completed drop. I usually end up selecting all tables and the drop option three times in a row in phpMyAdmin.
What does a good developer do when he’s forced to do something boring repeatedly? He automates it. I’m using minion-importer to quickly drop the entire schema and rebuild it from the previously exported SQL dump.
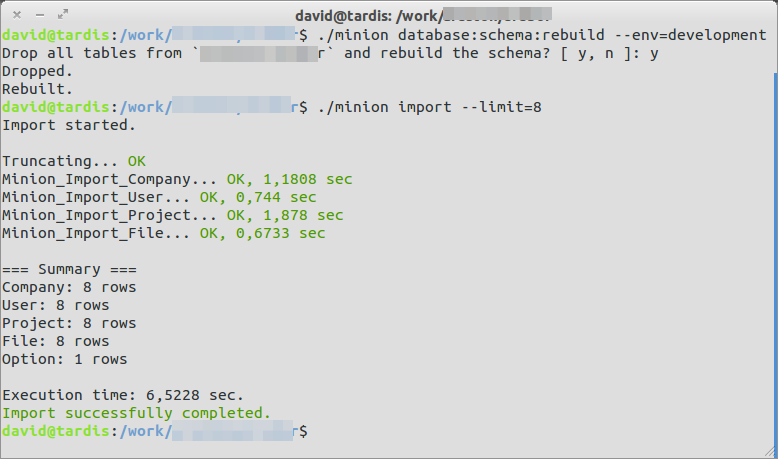
The dump contains some initial data rows, but it’s always good to develop with a bigger example dataset. fzaninotto/Faker to the rescue. It’s a PHP library that generates random test/sample data. Minion-importer has the skills to generate a number of sample rows for each table (8 in the above image).
I’ve changed the ERD model, exported it into SQL and rebuilt the development database to apply the change. This goes on for N iterations right up until initial deployment to Production.
Production / Maintenance
The production database is sacred. Thou shalt not drop / truncate / destroy its records. Therefore, the previous approach of dropping the whole database and rebuilding it from scratch does not apply when you have to preserve client data.
Time to introduce schema migrations. I’ll use Phinx to describe my changes. Phinx is a relatively new PHP tool for reliably managing the state of the database. It takes more time to describe each change to the database (hence the reason why it’s preferable to drop/build during development), but the added benefit are worth it:
- Changes to the schema are described (in most cases) in a non-destructive manner (adding a column doesn't result in the loss of the table)
- It's auditable - you always know the state and history of the database
- It's automatable - run database migrations from your build script
- You can undo changes, effectively returning the database schema to an earlier state
You might want to use migrations from the start when working in a team or wanting increased audit / version history. I’m a lone developer for the moment and the changes I do before deployment don’t need to be traceable in such detail… and there is always a VCS. You do use a VCS, don’t you?
I’ll still be updating my Workbench model as I describe each change in my migrations. I want an up-to-date visual representation of my database and if I ever need to create a new instance of the system I can start from the SQL dump again.
End-of-life
All software systems die. Whether it’s in twenty years (not many systems are coded so well) or in a next dozen-or-so months, it doesn’t matter. A good developer plans for the death of his system from the start.
From the database perspective, two things are important: getting the data out (most likely importing it into the new, replacement system) and archiving the schema and data for backup / archival purposes.
Getting the data out might be resolved with a simple CSV dump or your code might be good enough to provide an API for that (read about API-centric design, a rising trend in designing collaborative and accessible systems). Data archival is even simpler - gzip the database and press the big red button to permanently destroy the production database. Please be absolutely, positively, 101% sure the client and the company WANT this to happen and all valuable data has been extracted. There really should be cake and a big red button for such events. Let ‘em die with honor.
This is one of many ways to manage the life of a database. I find it to be fast and reliable, two reasons to keep at it. Please let me know what you think, any suggestions to improving the process are welcome. How do you manage the life of your databases?